
From Bug Catcher to Behaviour Guardian: QA’s New Mindset for AI
Article written by Asma Zoghlami
AI incidents surged by 56.4% in 2024, reaching a record high of 233 cases – the most ever recorded in a single year (Stanford HAI, 2025 AI Index).
These aren’t just technical glitches. They’re systems that pass traditional quality checks yet still amplify bias, break trust, and trigger costly post-launch firefighting. Organisations are deploying AI that works as designed but still causes serious harm. In our previous article, we explored why AI systems fail and why governance frameworks, while essential, aren’t enough on their own. AI testing and governance provides the principles and tools like bias detection, transparency dashboards, compliance workflows, but these only create impact when enforced through continuous operations.
That’s where Quality Assurance becomes critical. But here’s the problem: traditional QA was built for a world that no longer exists.
Building on that foundation, this article examines how QA must evolve to meet the demands of AI. Traditionally, QA has focused on validating functionality, performance, and usability, ensuring systems are reliable, stable, and aligned with requirements. Today’s AI systems introduce new challenges such as ethical risks, lack of explainability and complex decision-making. To meet these demands, QA must move beyond its traditional role. It needs to evolve from validating outputs to shaping trust and enabling accountability.
These warning signs raise a critical question: Is QA as we know it obsolete in the AI era? That’s the question this article explores.
The Costly Reality
Senior leaders tell us their biggest fear isn’t that AI will fail in testing – it’s that it will fail after launch, when reputational damage is expensive, urgent, and public. Traditional QA can’t catch what it wasn’t designed to see: bias drift, contextual failures, and ethical blind spots that only emerge in production.
Traditional QA: Built for a World That No Longer Exists
Quality assurance, as traditionally practised, no longer aligns with the realities of AI systems. It was built for deterministic logic and predictable workflows, where systems followed predefined paths and the same input consistently produced the same output.
This approach worked because traditional software operated within strict specifications and consistent behaviour. QA could therefore depend on static defect tracking, functional correctness checks, and binary pass/fail criteria to assess quality. In such settings, its role was to verify alignment with requirements, detect bugs early, and maintain system stability through repeatable tests. This predictability enabled characteristics such as:
- Deterministic test case: Designing tests with predictable inputs and outcomes, enabling precise coverage, easy automation, and consistent validation across environments.
- Functional validation: Validating that every feature behaves exactly as specified, ensuring alignment with requirements and enabling confident, repeatable validation.
- Binary pass/fail criteria: Exhaustive test cases and automated scripts could confidently declare success or failure, supporting high test coverage and rapid feedback.
- Regression stability: Making sure existing features still work after changes, enabling fast, confident testing before releasing new versions to production.
- Static defect tracking: Capturing and resolving bugs in a controlled environment, enabling clear root cause analysis and efficient resolution.
- Traceability mapping: Linking test cases directly to specific requirements and defects, enabling clear visibility into coverage, impact, and resolution status.
These capabilities rely on system determinism, a guarantee that no longer exists in the world of AI. When systems begin to learn, adapt, and produce outputs that vary with data, context, or other factors, the foundations of traditional QA start to crack.
The qualities that once made testing reliable and straightforward: predictable outcomes, repeatable execution, and transparent logic, are becoming difficult to enforce. This is where traditional QA starts to break down.
Challenges in Testing AI Systems
AI systems, particularly those driven by machine learning and large language models, don’t behave like traditional software. They learn from data, adapt to context, and often produce different outputs even when given the same input.
The result? Five critical challenges that traditional QA can’t handle:
- Unpredictable behaviour: The same input can produce different outputs. For instance, a language model may generate multiple valid responses to a single prompt. This variability breaks assumptions of repeatability and makes it challenging to automate tests reliably.
- Rigid testing doesn’t fit: Traditional test cases rely on fixed rules and expected outcomes, but the variability of AI systems makes fixed validation approaches ineffective. Tests may:
- Flag valid variations as failures
- Approve technically correct responses that meet test criteria, such as matching expected keywords, format, or structure, but are unclear or misleading because tests lack reasoning about quality and intent.
- Break frequently as models evolve, requiring constant updates
- Failure is not always a defect: In AI, unexpected results aren’t always bugs, they can show how the model has learned from its training data. Traditional QA often treats deviation as failure, but in AI, variation is often normal and expected.
- Performance shaped by context: AI system performance can vary depending on inputs, user behaviour, or deployment conditions, especially when real-world data differs from what the system was trained or tested on. This makes it difficult to predict outcomes and maintain stability across different scenarios.
- Lack of ground truth: Many AI tasks don’t have a single correct answer. This makes binary pass/fail judgments ineffective and calls for new ways to assess quality, such as confidence scores, rankings, or human-in-the-loop evaluation.
Traditional QA assumes stability and predictability. AI systems are dynamic and context-sensitive, so quality assurance must evolve. The challenge is no longer just catching bugs, it’s understanding behaviour.
The Shift: From Bug Catcher to Behaviour Guardian
To understand this evolution, let’s visualise the shift:
Figure 1 illustrates the evolution from traditional, deterministic practices to adaptive, behaviour-focused strategies for AI systems. Traditional QA assumes predictable behaviour: fixed inputs produce fixed outputs validated through binary pass/fail checks. In contrast, QA for AI systems must handle probabilistic behaviour, multiple possible outputs, and continuous monitoring of risk and performance. This shift demands a new mindset, replacing static validation with dynamic oversight.
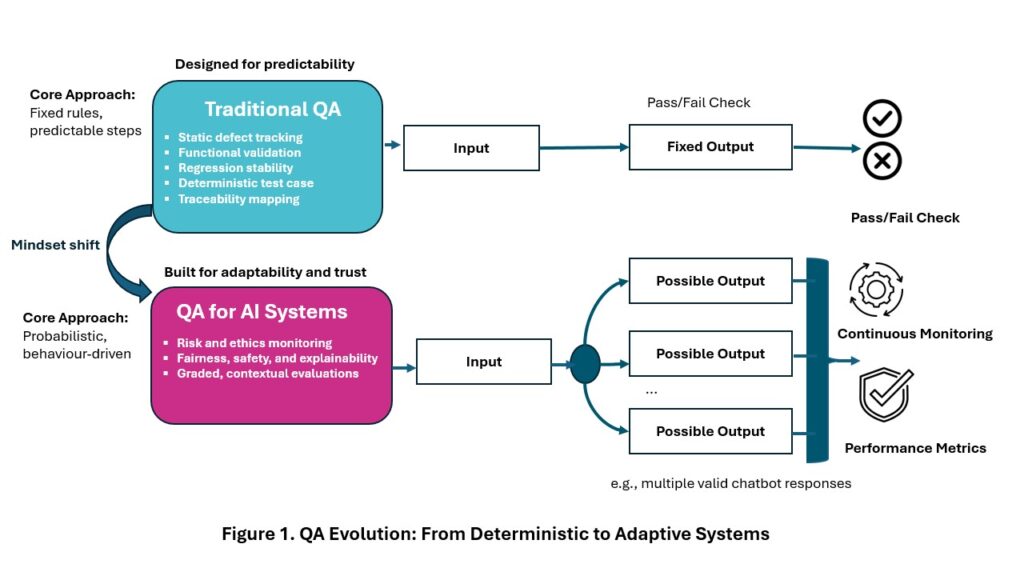
As AI systems challenge traditional QA, the discipline must adapt. It’s no longer enough to validate fixed outputs. QA must assess behaviour under real-world, dynamic conditions.
This evolution expands QA’s role to continuous oversight, ensuring AI systems:
- Perform reliably across varied contexts.
- Operate safely under stress or unexpected conditions.
- Act ethically and maintain fairness over time.
Five Pillars That Redefine QA for AI
The pillars that define the foundation of AI Quality Assurance are illustrated in Figure 2 and explained in detail below.
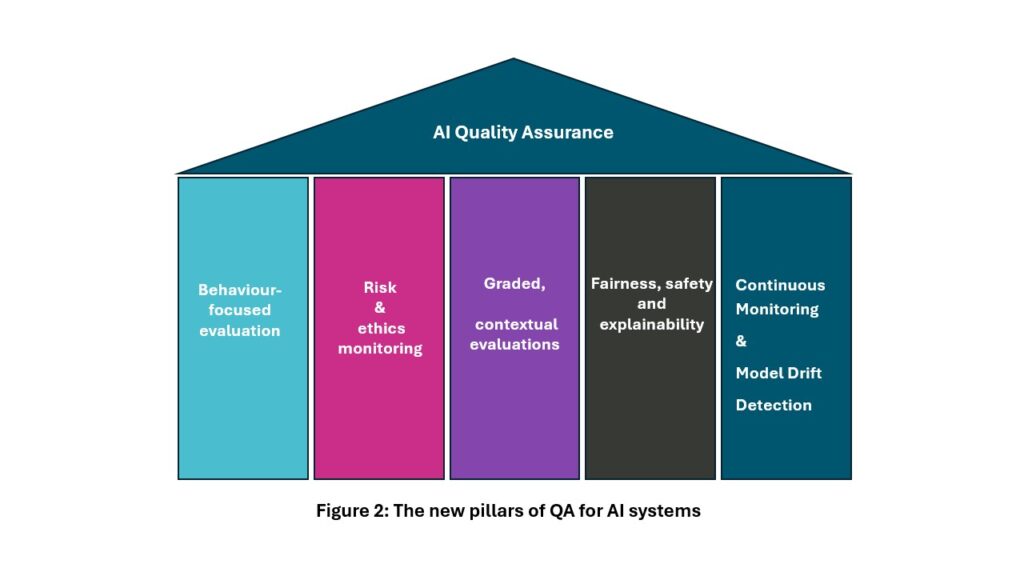
Behaviour-focused evaluation
QA looks at how an AI system behaves in real-world situations, not just single outputs. The focus shifts from checking correctness to assessing whether the system responds consistently, appropriately, and reliably under varying conditions. The goal is to understand overall behaviour patterns, not just individual results.
Real-world example: Testing a customer support chatbot’s response to: “How do I cancel my subscription?”
Traditional QA would check: “Did it provide the correct cancellation steps?”
Behaviour-focused QA asks: “Is the answer clear, helpful, respectful, and safe, and does the chatbot consistently maintain these qualities across polite queries, angry complaints, vague inputs, and unexpected messages like jokes or personal stories?”
Risk and ethics monitoring
AI systems introduce risks such as bias, misuse, and ethical violations. QA must integrate bias detection tools, fairness audits, and misuse simulations into testing workflows. Monitoring needs to be proactive and ongoing, with clear steps for escalation when risks appear. Collaboration with legal and compliance teams is essential to ensure every action aligns with governance principles and regulatory frameworks.
Fairness, safety, and explainability
QA ensures outputs are fair, safe, and transparent, not just functional.
- Fairness: No group is disadvantaged. Data and behaviour should support equal treatment.
- Safety: Avoid harmful outcomes and unintended actions. Maintain stability under stress.
- Explainability: Decisions should be easy to explain to both users and stakeholders.
Continuous Monitoring and Model Drift Detection
Unlike traditional QA, which assumes stability after release, AI systems are dynamic. They evolve through exposure to new data and respond differently as their deployment contexts evolve, meaning their behaviour can shift over time. This makes continuous monitoring essential, not just for performance, but for fairness and reliability. For QA teams, catching model drift is vital to maintaining system accountability and preventing failures that go unnoticed.
Graded, contextual evaluations
Binary pass/fail testing is no longer adequate for AI systems. Instead, quality assurance should adopt graded scoring across multiple dimensions such as clarity, usefulness, reliability, safety, and risk.
AI behaviour shifts with context, input, configuration, and user intent, making simple “valid or deficient” checks meaningless. Graded scoring provides metrics across clarity, consistency, and safety: high scores indicate strong performance under tested conditions, while low scores expose gaps that guide retraining and fine‑tuning.
Example: Testing a customer support chatbot’s response to: “How do I cancel my subscription?”
Grade 1.0 (Clear and accurate)
“Go to Settings > Billing > Cancel Plan.”
Grade 0.5 (Vague/misleading)
“Subscriptions are managed through your profile.”
Grade 0.0 (Harmful/should be blocked and addressed)
“Delete your account permanently.”
What’s Next: Can One QA Strategy Handle All AI Models?
As QA evolves from predictable software to complex AI systems, its mission transforms. It’s no longer just about catching bugs, it’s about evaluating behaviour, ensuring fairness, and safeguarding user trust. In the AI era, QA is a continuous function embedded across the AI lifecycle, helping systems remain reliable and transparent as they adapt over time. Generative, predictive, and agentic models each introduce distinct risks and challenges. In our next article, we’ll explain why one-size-fits-all QA falls short, and what a tailored approach looks like.
To discuss this topic in person with Dr Asma Zoghlami, join our AI Breakfast Briefing on 22 January 2026 at The Wolseley City, London.
If you can’t join us, register for our AI workshop so we can help you design the right strategy for your needs.
